


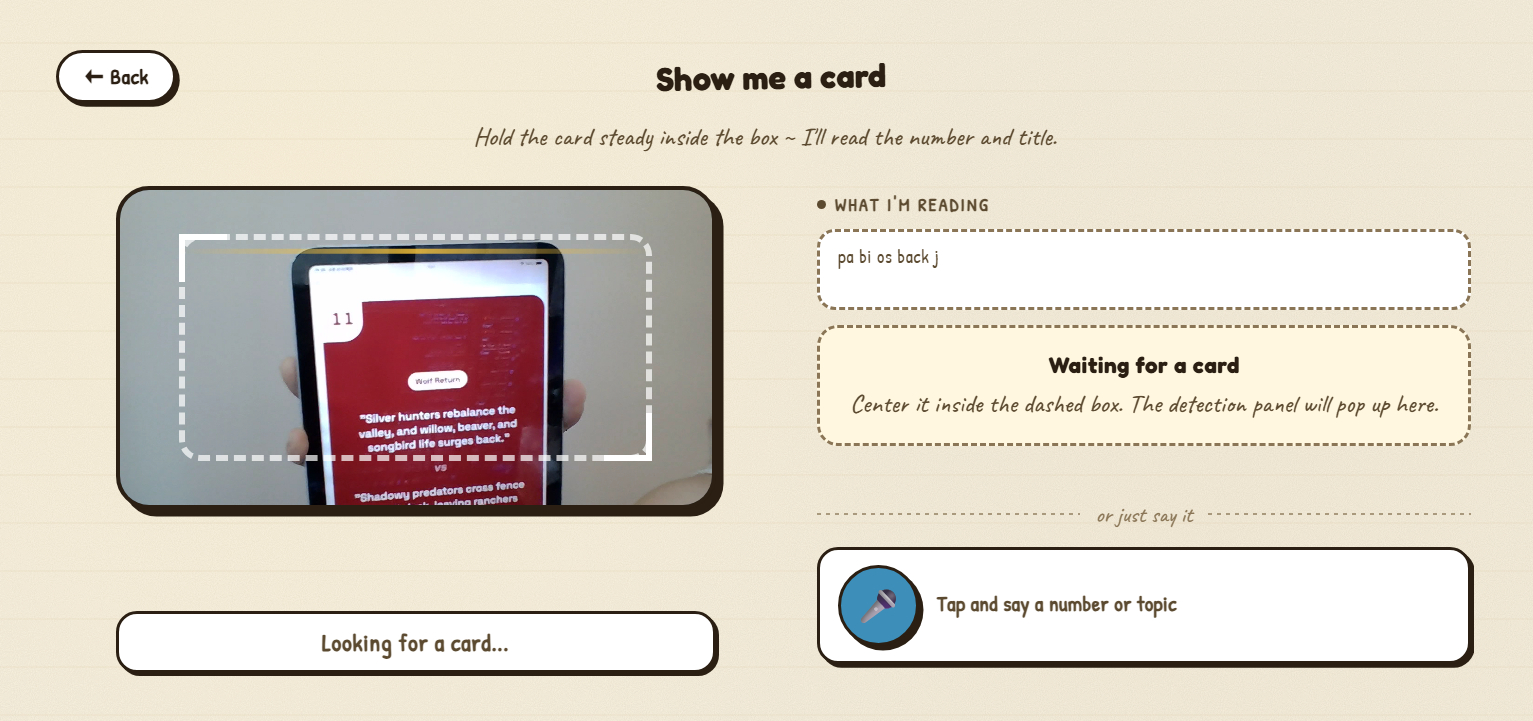

Prompt is a voice-first AI literacy game for kids age 10+, running fully on-device on an NVIDIA Jetson AGX Thor. A child picks up a printed reflection card, holds it to a webcam, reads the scenario aloud, and a kind AI coach responds with feedback on what kids think aloud.
The system trains three cognitive habits that traditional media literacy curricula struggle to build: spotting hidden framing, recognizing emotional manipulation, and writing prompts that surface multiple viewpoints from an AI. Speech-to-text, the LLM coach, text-to-speech, and card OCR all run locally — no cloud, no per-session cost, no kid voices leaving the device.
Kids today encounter AI-generated content, algorithmic feeds, and emotionally engineered media before they have the cognitive tools to recognize what's happening. Traditional media literacy curricula are reading-heavy and didactic — they tell kids what to think rather than build the muscle of noticing.
Three habits are missing in most kids' (and many adults') media diet:
| Habit | What it looks like |
|---|---|
| Frame awareness | Recognizing the same fact packaged through different lenses ("space relics" vs "space junk") for different audiences. |
| Emotion recognition | Noticing when a post is engineered to hijack a feeling — fear, outrage, urgency — before passing it along. |
| Prompt literacy | Knowing how to ask AI in ways that surface multiple viewpoints instead of locking into one. |
Prompt drills these three habits through spoken reflection instead of multiple choice. The kid reads a card, says aloud what they notice, and the coach responds.
The whole stack runs locally, by design. Children's voices and answers should not leave the device. Cloud APIs would also create latency (mic → cloud → response = 3–8s on residential broadband, vs 2–4s entirely local) and per-session costs that make this unviable in classrooms.
The deck is split into two card families and four problem types, each colored to match the printed card:
| Family | Problem Type | What the card does |
|---|---|---|
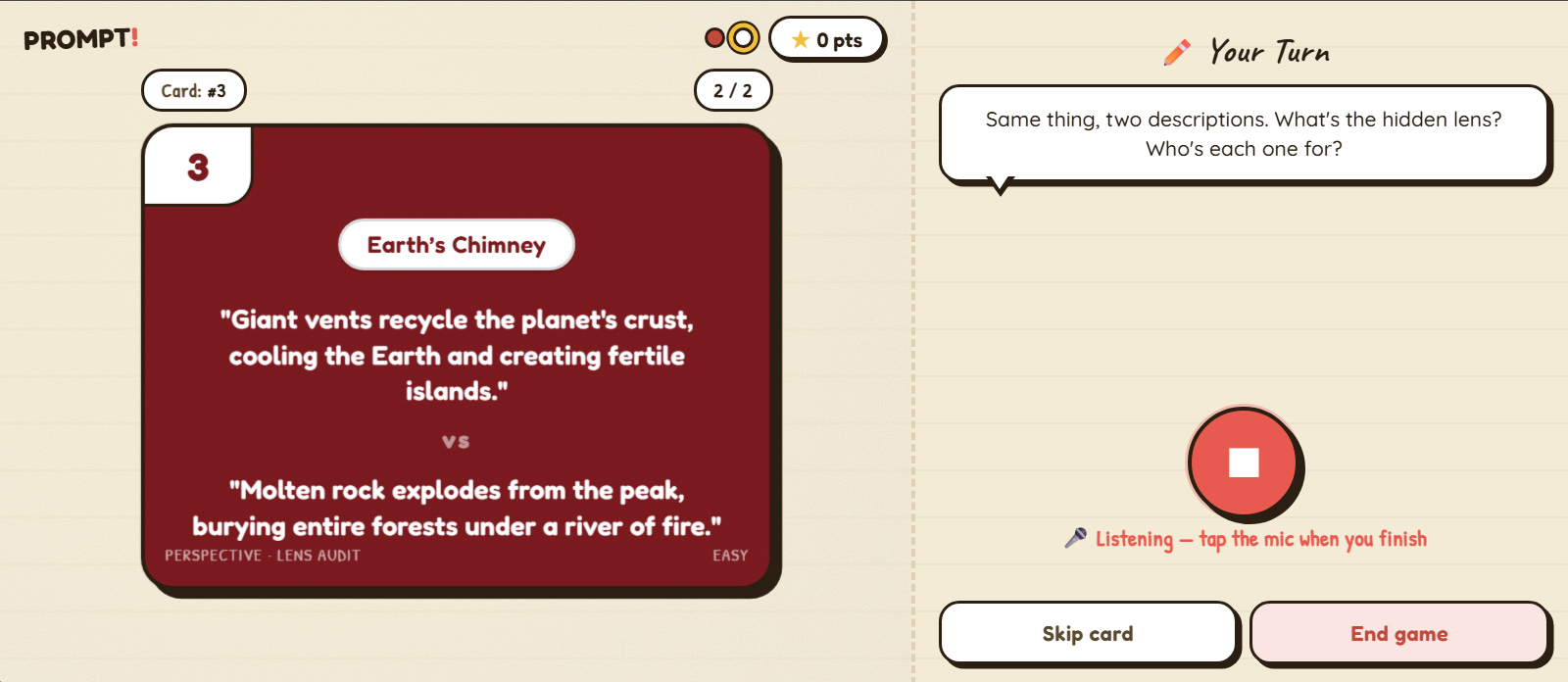
| Discernment | Perspective Lens Audit | Two descriptions of the same thing — find the hidden lens. |
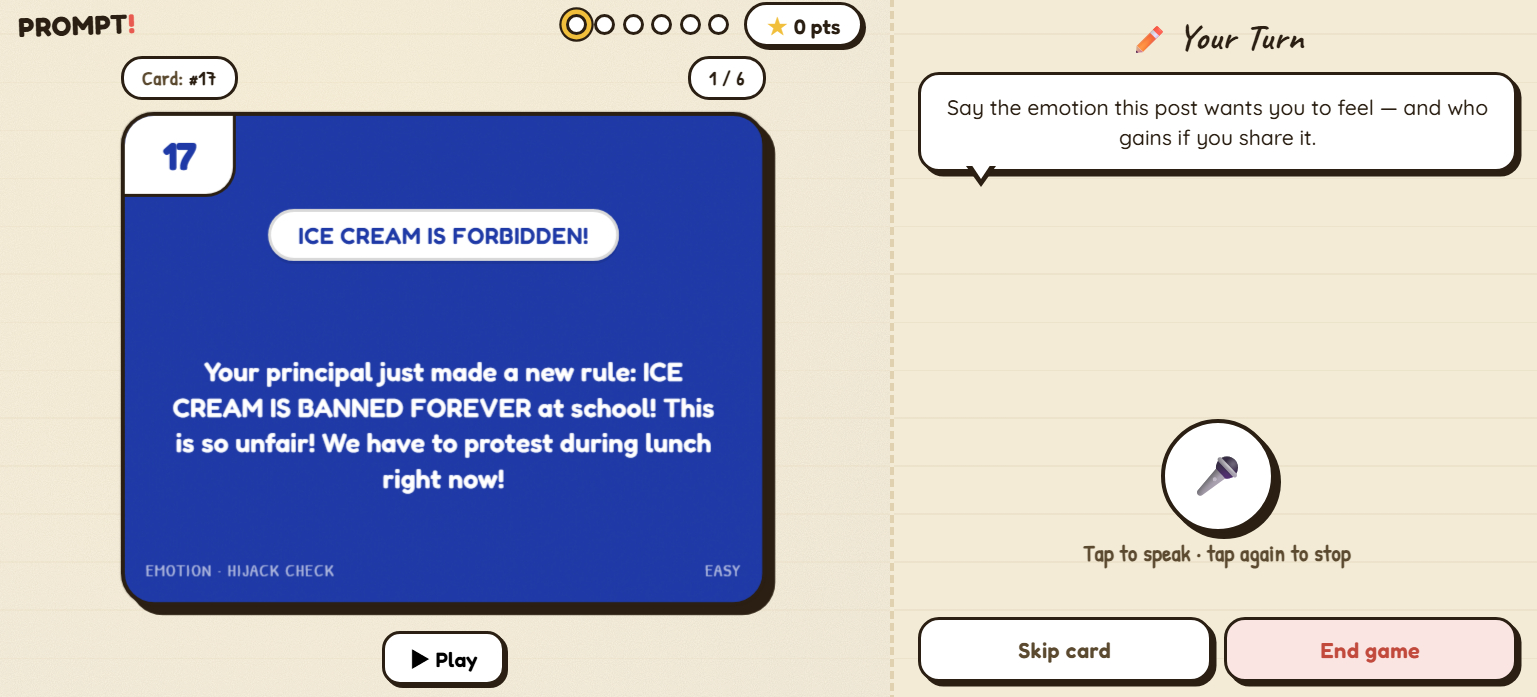
| Discernment | Affective Hijack | A post engineered to grab a strong feeling — name the feeling AND who gains if you share. |
| AI Usage | Bias Inverter | An AI answer secretly centers one viewpoint — propose a follow-up prompt that exposes the bias. |
| AI Usage | Task Decomposition | A big messy task — break it into ordered sub-prompts. |
Two ways to play. Scan mode: the kid holds a printed card to the webcam, the system recognizes it, and answers one card at a time. Quick Play: the system deals six cards balanced across both decks with a soft easy-to-hard ramp.
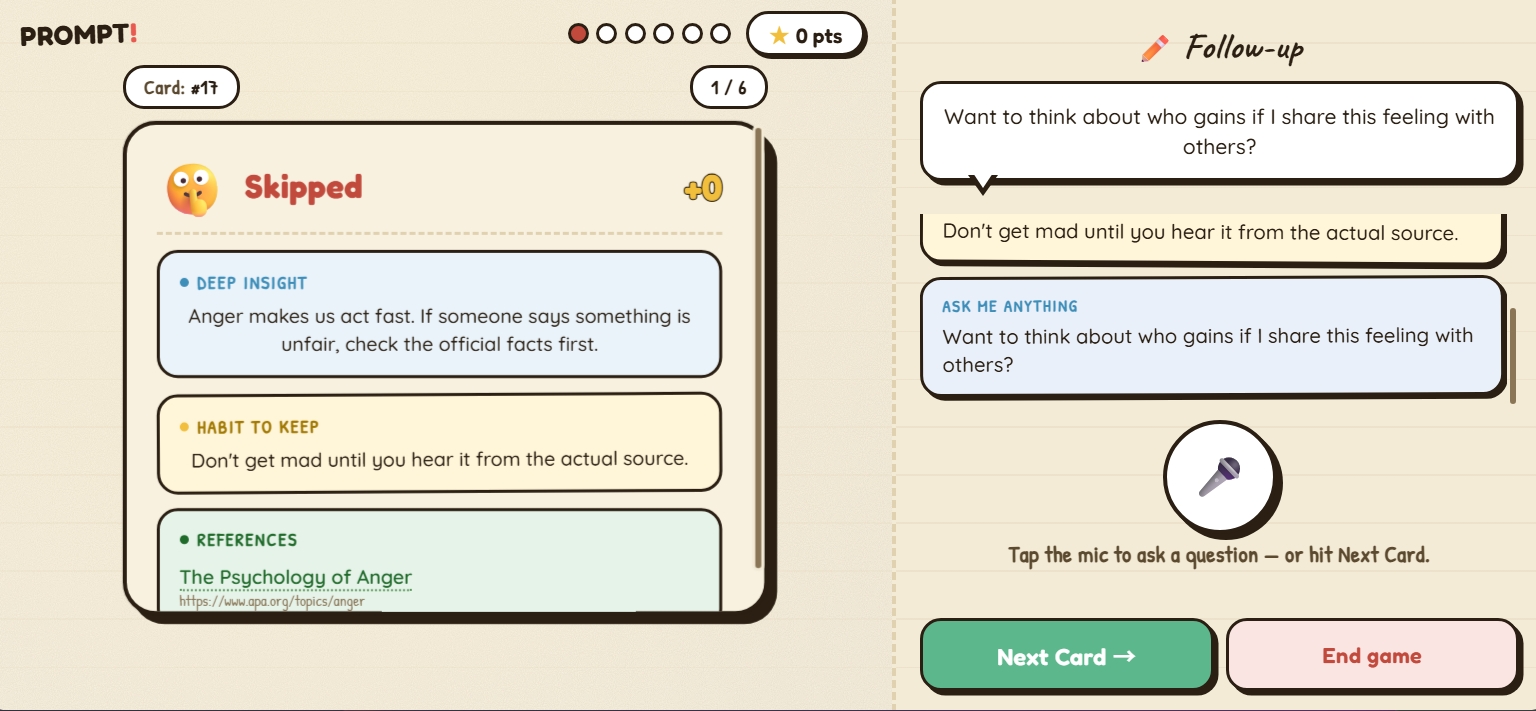
Each card uses the same loop. The coach reads the scenario aloud. The kid taps the mic and speaks. The card flips, and the coach delivers three short lines: a reaction to what the kid said, a habit to keep, and an invitation — "Curious about anything else here?" That third line opens a free-form follow-up Q&A scoped to the card and to general AI/media literacy, capped at four follow-ups per card so it never runs forever.
Each answer falls into one of five tiers — deep (10 pts), mid (7), surface (3), off (0), or silent (0, no speech). The most opinionated decision in the project is that the LLM never decides the score. A deterministic rule engine matches the kid's words against semantic families: emotion words, motive words, meta-awareness words, audience cues, reframing verbs, and so on.
The reason is consistency. LLM grading drifts — the same answer on the same card scores differently across runs. Kids deserve consistent feedback, and educators deserve a rubric they can validate.
A child who says "I'd ask the AI to rewrite this from a worker's view" hits rewrite (strong reframe) plus worker (group noun matching the suggested prompt) and reaches deep. "There might be another side" — only weak reframe markers, scores surface. Same logic, every time.
There is one tightly-scoped exception for bias_inverter: a single-word LLM judge at temperature 0.1 can promote a mid to deep when the kid's reframe is genuine but uses novel vocabulary. It can only promote upward, never demote — protecting against silent grade inflation.
The whole system runs on a single Jetson AGX Thor with no cloud round-trips at runtime.
| Layer | Technology | Why this choice |
|---|---|---|
| STT | Whisper small | Best accuracy/latency tradeoff for kid speech on Thor's GPU. |
| LLM | Llama 3 8B Q4 via Ollama | Smallest model that produces consistent 3-line, kid-friendly outputs. |
| TTS | Kokoro 82M (af_heart voice) | 3s cold start (down from 25s with ChatTTS in v2), seamless multi-sentence audio. |
| OCR | Tesseract.js v5 (browser-side) | Keeps Thor's CPU/GPU free for Whisper + Llama 3 + Kokoro. |
| Backend | FastAPI + uvicorn | Async-native for streaming TTS, automatic OpenAPI docs. |
| Frontend | Vanilla HTML + JS | One screen, one state machine — no build step needed for a kiosk. |
The card scanner is worth a closer look. Tesseract.js runs entirely in the browser and does two-signal matching: it has to find both the #NN card number AND distinctive title words before it accepts a match. To eliminate flicker on a moving card, the same match has to appear in two consecutive frames before the confirmation panel pops up. Manual voice fallback also exists — the kid can just say "the wolf one" or "card fourteen" and the system handles ordinals, English number words, and fuzzy title matching.
The thing that makes the experience feel alive is that everything happens in 2–4 seconds, locally, with no spinner-induced anxiety:
mic → Whisper STT ~0.6s
→ rule scoring ~0.01s
→ Llama 3 feedback ~1.5s
→ Kokoro TTS ~0.3s
→ playback immediate
No part of this pipeline depends on the internet. The Jetson is the entire stack.
The functional layers were stable by v4. v5 was the first release where the look matched the spirit of the project — a kid's reflection notebook, not a dark-mode dev console.
The whole interface was rebuilt around a hand-drawn aesthetic. Cream paper background with subtle pencil-noise texture and faint horizontal rule lines. Every button has a hard ink outline plus an offset marker shadow. Entry cards tilt at ±1.2°, sticky-note bubbles wobble slightly, underlines under headers are SVG squiggles instead of straight lines.
Card colors map directly to problem type, matching the printed physical decks: deep crimson for perspective lens audits, cobalt blue for emotional hijacks, forest green for bias inverters, caramel brown for task decomposition. The on-screen card uses the same notched white corner and pill-shaped title as the physical card the kid was just holding, so the visual handoff between paper and screen feels continuous.
Three fonts do the work: Fredoka for rounded display, Caveat for handwriting, Patrick Hand for pencil-print labels. Quicksand handles body text. Everything sizes with clamp() so the same UI fits both the 7" Thor touchscreen and a Firefox window with browser chrome.
The kiosk runs on commodity parts plugged into the Jetson:
- Compute — NVIDIA Jetson AGX Thor Developer Kit
- Display — 7" HDMI touchscreen with built-in speaker
- Camera — Logitech C270 USB webcam (also serves as the microphone)
- Power — USB-C PD adapter, plugged into the port farther from HDMI; touchscreen data cable goes in the nearer USB-C port
That last detail matters more than it should — getting the two USB-C ports right is the difference between a working touchscreen and one that displays but won't respond to touch.
The project went through five iterations, each fixing a specific UX problem.
v1 was multiple choice — A/B/C/D cards, Piper TTS, fixed sequence. Kids guessed. The tap interaction defeated the spoken-reflection goal entirely.
v2 rewrote the whole card schema around open-ended scenarios with scoring anchors. Two card families, four problem types, tiered scoring with ChatTTS. But ChatTTS had a 25-second cold start with audible per-segment stalls, "Next Card" was bugged and repeated card 1, grading was too strict, and there was no way to end the game early.
v3 swapped ChatTTS for Kokoro (cold start dropped to 3s), fixed the next-card bug, added an end-game button, and rewrote the rule engine around semantic families instead of prefix-stemming. A stress test across 48 realistic answers showed balanced tier distribution: deep 12 / mid 11 / surface 9 / off 8 / silent 8.
v3.1 added free-form follow-up Q&A — feedback expanded from 2 lines to 3, a new /api/followup endpoint scoped to the current card and to general AI/media literacy, soft-redirects on off-topic questions, and a per-card cap of 4 follow-ups.
v4 added physical card scanning. New HOME with two big entry points, a SCAN screen with live camera preview and animated laser sweep, browser-side OCR via Tesseract.js, two-signal matching, two-frame confirmation, manual voice fallback. "Next Card" became "Scan Next Card" in scan sessions and returned the kid to the scanner.
v5 rebuilt the entire UI as the sketchbook edition described above.
The project produced a fully working kiosk-style game that:
- Runs end-to-end on a single edge device with no internet at runtime
- Recognizes printed cards by
#NNand title in 1–2 seconds under typical room light - Returns coach feedback in 2–4 seconds per turn (STT + rule scoring + LLM + TTS combined)
- Holds 26 discernment cards and 26 usage cards across four problem types with consistent rubrics
- Supports free-form follow-up Q&A scoped to AI/media literacy without drifting to homework help
- Scores answers deterministically through a rule engine that an educator can validate and tune
The hardest decisions in this project weren't technical — they were about restraint.
Restraint about scoring: it would have been easier to let the LLM grade everything, but consistency mattered more than vocabulary coverage. The rule engine plus a tightly-scoped LLM judge for one problem type produces feedback an educator can actually trust.
Restraint about the UI: the sketchbook redesign meant deleting a lot of polish that looked good in isolation but read as "tech product" rather than "kid's notebook." The physical card and the on-screen card had to feel continuous, and that meant subordinating screen design to print design.
Restraint about the follow-up Q&A: capping at four per card felt mean at first, but the alternative was sessions that drifted into trivia and homework help, undermining the AI-literacy framing. The cap protects what the game is for.
The bigger insight is that edge AI changes what's possible for kids' tools. A device that processes a child's voice locally, gives feedback in 2–4 seconds, costs nothing per session, and keeps everything on the device opens design space that cloud-based equivalents simply can't reach — privacy, latency, deployability in classrooms and libraries with poor connectivity, and zero ongoing cost.
Future directions include cheaper hardware tiers (Pi 5, Orin Nano Super) at roughly 1/10 the cost of Thor, a community-contributed card platform where teachers and parents can submit and review new cards, and a hosted web-only version that shares the card JSON and rule engine with the local box — turning Prompt from a one-off install into a node in a larger AI literacy ecosystem.






